
Giuseppe Specchio
Maresciallo,
Analista di Laboratorio presso il Ra.C.I.S. - Roma
addetto al Reparto Tecnologie Informatiche Sezione Telematica.
1. Introduzione
La differenza sostanziale tra le indagini classiche e quelle in materia di criminalità informatica in Internet è l’"aterritorialità"(1).
Tale vincolo solleva problemi a diversi livelli:
- territoriale: assenza di confini ben definiti;
- livello processuale: chi è competente a fare cosa;
- legislativo: Autorità Giudiziaria competente ad indagare o giudicare.
Tali elementi, uniti a vincoli di carattere tecnologico di seguito descritti, ostacolano, se non rendendo impossibile, l’operazione di ricostruzione del percorso utilizzato dall’autore del reato, non consentendo così l’individuazione della postazione dalla quale è stato posto in essere il comportamento illecito.
A tale risultato potrà pervenirsi unicamente seguendo a ritroso il cammino dell’informazione illecita, dal destinatario ad un provider (sovente con sede all’estero), e da questi sino al client dell’autore del reato.
Nel caso in cui la postazione sia nella disponibilità di più soggetti, sarà necessario correlare l’attività tecnico-investigativa con gli elementi di prova(2) ricavati con modalità classica(3), al fine di dimostrare una disponibilità univoca del mezzo di un determinato lasso temporale.
In questo articolo si farà uso di una simulazione di una querela sporta per diffamazione a mezzo Internet, ove tramite un’analisi delle varie fasi che caratterizzeranno l’indagine, verranno fornite delle best practices da attuare nel contesto della Network Forensics, ovvero un contesto c.d. post mortem.
2. Sistemi d’identificazione degli autori del reato
Qualora bisognasse svolgere operazioni di analisi inerente un sistema di rete può essere conveniente, in prima approssimazione, suddividere le tematiche legate al Network Forensics in due classi, a seconda si tratti di live analysis o post mortem analysis, come riportato in Figura 1, per una collocazione nell’ambito codicistico penal procedurale che separi, seppur in modo non esaustivo, lo stato pre - e post - discovery(4).

In questo paragrafo verranno tralasciate le problematiche della live analysis, le quali esulano dall’obiettivo di quest’articolo, ma ci si addentrerà sul rinvenimento e l’esame, in ottica post mortem, delle attività correlate all’utilizzo per fini criminali della rete.
Per aiutarci nell’excursus investigativo, faremo riferimento ad un’ipotetica, quanto fantasiosa acquisizione di notizia di reato consumato a mezzo Internet (querela o denuncia che sia), come quella riportata di seguito:
«Io sottoscritta Sig.ra Lady Oscar nata a Roma il 27/08/1965 ed ivi residente in via dei fori imperiali n. 3, impiegata presso la società Walt Disney Inc. di Roma, denuncio quanto segue: ... "…In data 15 novembre 2008 ho scoperto che un messaggio, altrettanto oltraggioso e lesivo della mia persona, era stato postato e visibile al mondo intero, su un sito raggiungibile attraverso l’URL http://www.youtube.com/watch?v=ErdZLgRsn1U che mi riguarda. Non ho idea di chi possa aver fatto tutto ciò. Chiedo la punizione del colpevole per quant’altro ravvisabile". Roma, 15 novembre 2008».
L’Ufficiale di Polizia Giudiziaria, a contrario del contesto del mondo reale, avrà a sua disposizione generalmente solo pochi ed incerti elementi:
- dati relativi alla denunciante;
- data in cui la denunciante si è accorta della presenza del messaggio diffamatorio;
- URL (Uniform Resource Locator) del sito su cui dovrebbe essere visualizzato il messaggio (informazione sovente ricavata dalla pagina web stampata dalla parte offesa);
- ipotesi di reato, cioè diffamazione art. 595 c.p. co. 3;
- istanza di punizione del responsabile o dei responsabili è l’elemento essenziale per la validità della querela, la cui mancanza potrà compromettere l’intero iter investigativo.
Sarà suo compito preliminare ricavare informazioni utili al proseguimento delle indagini, le quali come vedremo facilmente camuffabili. Segue una breve descrizione di tali elementi tecnici.
2.1 L’Uniform Resource Locator
L’Uniform Resource Locator o URL è una sequenza di caratteri che identifica univocamente l’indirizzo di una risorsa in Internet, come ad esempio un documento o un’immagine.
Considerando l’URL http://www.youtube.com/watch?v=ErdZLgRsn1U, riportato nell’esempio di querela indicata al paragrafo precedente, esso rappresenta univocamente il video oggetto del contenzioso. Una definizione formale di questo identificativo, si trova negli RFC(5) 1738 e 3986 della IETF.
Ogni Uniform Resource Locator si compone normalmente di sei parti alcune delle quali opzionali:
protocollo://<username:password@>nomehost<:porta></percorso><?querystring>
- protocollo: descrive il protocollo da utilizzare per l’accesso al server. I protocolli più comuni sono l’HTTP, HTTPS, FTP, ecc. Se il protocollo non viene specificato, generalmente il browser utilizza "HTTP://" come predefinito;
- username:password@: è un parametro opzionale. Subito dopo il protocollo, è possibile specificare l’autenticazione (username e password) per l’accesso alla risorsa. Alcuni server consentono di specificare nell’URL le informazioni per l’autenticazione nel formato username:password@. Tale tipologia di autenticazione in URL risulta estremamente rischiosa in quanto le credenziali di accesso vengono inviate al server in chiaro. Inoltre, i server che non necessitano di autenticazione, non considerano in alcun modo i contenuti a sinistra del simbolo "@", questo sistema di autenticazione espone gli utenti al phishing(6).
Un URL creato ad arte può portare un utente ad una destinazione completamente diversa da ciò che ci si può aspettare.
Ad esempio: l’URL //www.carabinieri.it@www.oratifrego.net a prima vista sembra portare su Carabinieri.it ma in realtà la destinazione effettiva è www.oratifrego.net.
Da diversi anni, un update di Internet Explorer (832894) ha disattivato la funzione di autenticazione rendendo inefficaci i tentativi di phishing. Altri browser come Firefox, hanno mantenuto la funzione avvertendo tuttavia l’utente del possibile tentativo di phishing;
- nomehost: rappresenta l’indirizzo fisico del server su cui risiede la risorsa. Può essere costituito da un nome di dominio (es. www.carabinieri.it, ftp.giuseppespecchio.info) o da un Indirizzo IP (es. 208.12.16.5);
- porta: è un campo opzionale. Spesso confusa con il socket(7), è strutturata su 16 bit, di cui i primi 1024 (well known port number) vengono gestite direttamente dal browser (es. HTTP:80, SMTP:25, POP3:110, ...). Incontreremo un URL con porta esplicita solo in applicazioni ad hoc che girano su porte tra 1024 e 65535 (es. localhost:8080/concorsi/index.htm, 127.0.0.1:2020/index.asp);
- percorso: è un capo opzionale. Detto anche pathname nel file system del server che identifica la risorsa (generalmente una pagina web, un’immagine o un file multimediale). Se il nome del file non viene specificato, il server può essere configurato per restituire il file predefinito (es. index.php);
- querystring: è un campo opzionale. Se richiesto, al termine dell’URL è possibile aggiungere una query string separandola utilizzando il simbolo "?". La querstring è una stringa di caratteri che consente di passare al server uno o più parametri. Di norma, la query string ha questo formato:
[...]?parametro1=valore¶metro2=valore2.
2.2 L’Internet Protocol
L’indirizzo IP (dove IP sta per Internet Protocol) è l’elemento fondamentale che permette, all’interno di una rete di calcolatori, di individuare un nodo della rete stessa.
Gli indirizzi IP sono utilizzati dal protocollo IP per gestire l’instradamento delle comunicazioni tra tutte le macchine connesse a Internet. Internet è infatti emersa progressivamente dall’interconnessione di diverse reti basate su tecnologia IP.
L’indirizzo IP, in teoria, identifica quindi univocamente uno specifico computer o nodo di rete all’interno della rete stessa. Pertanto, nella ricerca di informazioni relative ad un computer crime, identificare un indirizzo IP "associabile ad esso" (l’indirizzo di un dispositivo che possono rappresentare la fonte di attacchi o il mezzo di attuazione di un reato) potrebbe portare all’identificazione del potenziale reo. Nella pratica, la situazione è più articolata, per una serie di ragioni di cui si parlerà nel seguito.
Come già anticipato, l’identificazione specifica degli elaboratori connessi a Internet è tuttavia garantita dall’univocità dell’indirizzo che viene loro assegnato in una precisa data ed ora, o sessione di collegamento alla rete (indirizzo IP). Esistono due versioni di indirizzi IP:
- IPv4 è strutturato su 32 bit a gruppi di 4 byte generalmente espressi in formato decimale (dotted-decimal) 0.0.0.0 … 255.255.255.255 (di cui alcuni riservati). Ad esempio la sequenza 195.32.69.2 viene codificato dall’elaboratore come la sequenza binaria 11000011.00100000.01000101.00000010.
Nella migliore delle ipotesi (utilizzo "ottimale" di tutti gli indirizzi) 32 bit sono sufficienti ad identificare univocamente a livello mondiale poco più di 4 miliardi di dispositivi. Nella pratica vi sono sia ragioni per cui questo numero è necessariamente minore, sia modalità di utilizzo di Internet che non richiedono la necessità di un’identificazione univoca del dispositivo sulla intera rete, e quindi permettono la "condivisione" di un indirizzo IP (si veda il paragrafo dedicato al sistema NAT per una spiegazione più dettagliata);
- IPv6 è l’evoluzione di IPv4, (IPv5 è una versione prototipale di protocollo di trasmissione real-time, mai implementata) la cui introduzione, avviata già nel dicembre ’95 tramite RFC 1883, è motivata dal fatto che a breve il numero di indirizzi IPv4 potrebbe essere insufficiente per rappresentare univocamente tutti i dispositivi collegati alla rete mondiale. IPv6 ha indirizzi costituiti da 128bit(8), rappresentati da 8 gruppi di quattro cifre esadecimale, separati dal simbolo ":".
Un esempio di indirizzo IPv6 potrebbe essere il seguente 3FFE:1900:4545:3:200:F8FF:FE21:67CF. Nel seguito della trattazione ci si concentrerà su IPv4, il protocollo ad oggi utilizzato per la quasi totalità del trasporto dati su Internet.
Vi sono alcuni aspetti infrastrutturali che caratterizzano le reti basate su IP (quindi Internet) di cui è opportuno tenere conto nel caso in cui si debba risalire all’indirizzo IP coinvolto nell’attuazione di un illecito. Infatti, come già accennato, vi sono alcuni "limiti" nell’affermazione secondo cui un indirizzo identifica "univocamente" un apparato in Internet e quindi tendenzialmente un utente, qualora s’ipotizzi una responsabilità da parte del proprietario del dispositivo nell’eventuale utilizzo dello stesso per scopi illeciti.
Tali limiti nell’associazione tra indirizzo IP rilevato e utente/proprietario del sistema utilizzato sono legati ad esempio ai seguenti aspetti, sui quali nel seguito si forniranno dettagli esplicativi utili ad orientarsi nell’ambito in questione:
- indirizzi IP pubblici e privati;
- NAT (traduzione di indirizzi);
- reti wireless aperte o punti di accesso alla rete non controllati;
- indirizzo IP statico o dinamico;
- Antiforensics, tramite anonimizzazione dell’indirizzo IP.
2.2.1 Indirizzi IP pubblici e privati
Vi sono due differenti tipologie di indirizzi IP, rispettivamente chiamate "indirizzi IP pubblici" e "indirizzi IP privati". Gli indirizzi pubblici sono allocati univocamente, ossia concessi in uso ad uno specifico soggetto che li attribuisce in ogni istante ad uno e un solo apparato sulla rete (o meglio ad una sola interfaccia di rete, nel caso di apparati multi-interfaccia). Questi sono gli indirizzi che permettono effettivamente di comunicare con qualsiasi altro sistema all’interno della rete Internet e che compaiono nelle "intestazioni", o "header" dei vari pacchetti di dati che viaggiano sulla rete. Gli indirizzi IP pubblici sono rilasciati dall’ICANN (Internet Corporation for Assigned Names and Numbers)(9) e sono divisi in "classi"(10).
L’ICANN è l’ente che assegna grandi blocchi di indirizzi ai RIRs (Regional Internet Registries), i quali a loro volta assegnano sotto-blocchi d’indirizzi ai LIRs (Local Internet Registries) o NIRs (National Internet Registries) i quali a loro volta allocano IP ai rispettivi ISP (Internet Service Provider), come riportato in Figura 2(11).

Quest’ultimi assegnano IP dinamici (se cambiano ad ogni connessione) o statici, in base al contratto con l’utente finale.
Gli indirizzi IP privati rappresentano alcune classi di indirizzi IPv4, definite dall’ RFC 1918, destinati ad essere utilizzati all’interno delle reti locali (LAN) per le comunicazioni all’interno di una singola "organizzazione" (in senso lato: un caso d’uso molto frequente è rappresentato dalle comunicazioni tra le macchine in una rete domestica) e che non possono essere utilizzati in
Internet (ossia, i
router Internet non operano l’instradamento per i dati spediti utilizzando questi indirizzi).
Per le reti private interne, dette comunemente Intranet, sono riservati tre agglomerati di indirizzi indicati in Tabella 1.
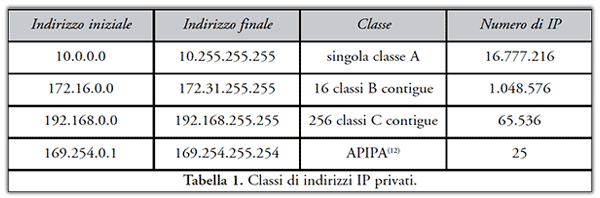
Non si ritiene utile qui entrare in ulteriori dettagli relativi al tema generale dell’indirizzamento IP, approfondendo invece nel prosieguo della trattazione aspetti di volta in volta utili.
Si tenga presente che, come già parzialmente intuibile da quanto accennato sopra, rilevare un indirizzo IP pubblico possa, in determinate condizioni, ricondurre ad un soggetto responsabile o coinvolto nelle attività sotto osservazione. Un indirizzo IP privato, qualora venisse rilevato al di fuori dell’organizzazione in cui sono originate le comunicazioni, non darebbe nessuna informazione sulle parti coinvolte poiché molti utenti potrebbero disporre contemporaneamente del medesimo indirizzo IP privato, in organizzazioni differenti.
2.2.2 NAT
NAT è l’acronimo inglese di Network Address Translation ovvero "Traduzione degli Indirizzi di Rete", conosciuto anche come network masquerading(13) e definito dal RFC 1631. È una tecnica che consiste nel modificare gli indirizzi IP dei pacchetti in transito su un sistema che agisce da router. A titolo illustrativo si veda Figura 3.
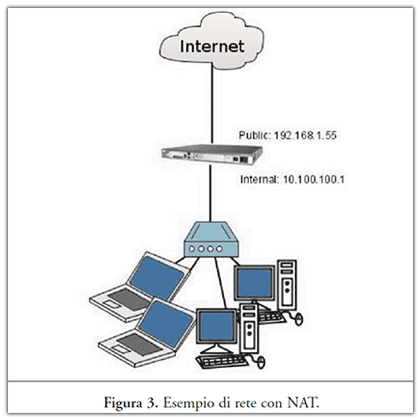
Le connessioni effettuate da un insieme di computer vengono "presentate" verso l’esterno come un solo indirizzo IP.
Questa tecnica è utilizzata per:
- risparmiare indirizzi IP pubblici (in quanto costosi);
- "nascondere" dall’esterno una rete privata.
Al fine di ottimizzare il range d’IP a loro assegnati, alcuni ISP utilizzano proprio questo sistema per dare servizi di connettività Internet ai propri clienti (es. FastWeb e H3G). Esistono tre varianti di tale sistema:
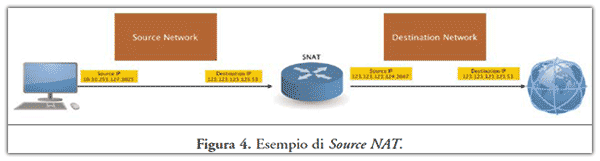
- Source NAT. Le connessioni effettuate da uno o più computer vengono alterate in modo da presentare verso l’esterno uno o più indirizzi IP diversi da quelli originali, quindi chi riceve le connessioni le vede provenire da un indirizzo diverso da quello utilizzato da chi le genera, come riportato in Figura 4;
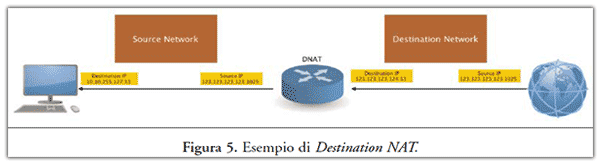
- Destination NAT. Le connessioni effettuate da uno o più computer vengono alterate in modo da essere dirette verso indirizzi IP diversi da quelli originali, quindi chi effettua le connessioni si collega in realtà con un indirizzo diverso da quello che seleziona, come riportato in Figura 5;
- Double NAT o Full NAT. Le connessioni effettuate da uno o più computer, tra reti LAN diverse, vengono alterate in modo da nascondere reciprocamente le due reti, quindi nascondendo reciprocamente le due reti.
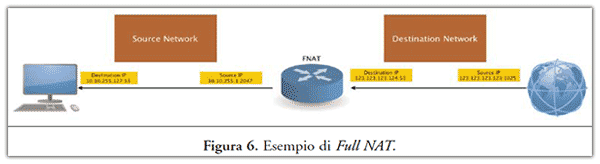
2.2.3 Wireless aperte o punti di rete non controllati
Un malintenzionato potrebbe utilizzare, qualora riesca a trovarne, accessi di rete non gestiti o non controllati per eseguire attività illecite.
Il caso più frequente è dato dallo sfruttamento delle connessioni wireless degli utenti domestici.
Talvolta, infatti, tali connessioni non sono protette e sono accessibili da luoghi pubblici, ad esempio nelle adiacenze dei palazzi che le ospitano.
In tal caso, un malintenzionato sarebbe in grado di eseguire l’illecito utilizzando tale connessione, garantendosi l’anonimato nell’accesso alla rete.
Anche le reti protette tramite WEP (Wireless Encryption Protocol), ossia il primo protocollo di protezione delle connessioni wireless introdotto, e di cui si sono subito rilevate le falle di sicurezza, non costituiscono un problema per chi voglia ottenere accesso a reti wireless.
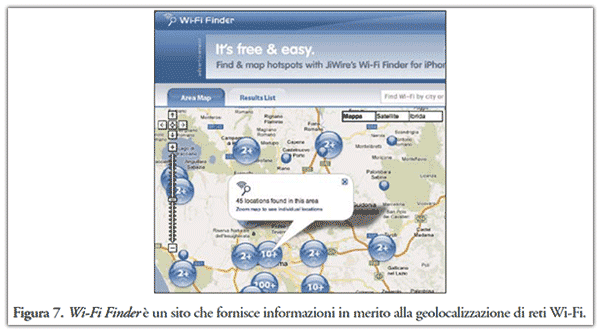
Si parla in questo caso di "wardriving", un’attività che consiste nell’intercettare reti Wi-Fi, in automobile, in bicicletta o a piedi con un laptop, solitamente abbinato ad un ricevitore GPS (Global Positioning System) per individuare l’esatta locazione della rete trovata ed eventualmente pubblicarne le coordinate geografiche su un sito Web, un esempio viene riportato in Figura 7.
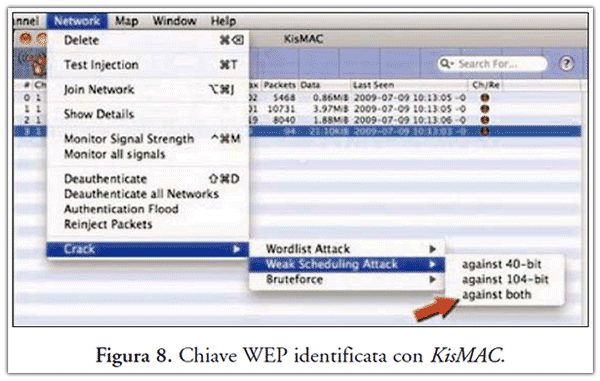
Il wardriving in sé consiste nel trovare Access Point (AP) e registrarne la posizione. Alcune persone, invece, infrangono le scarse misure di sicurezza tipiche di queste reti per accedere gratuitamente alla connessione, o addirittura alle risorse presenti nella rete violata. Si consideri che ad oggi per rompere la protezione "crackare" offerta dal protocollo WEP bastano pochi minuti mediante l’uso di software come "Aircrack", "NetStumbler", "Ministumbler", "KisMAC", quest’ultimo riportato in Figura 8.
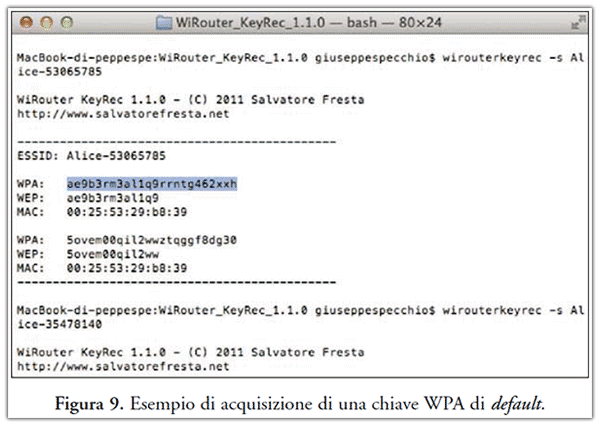
Non sono soggetti ad analoghe problematiche i router che utilizzano passphrase con protocollo WPA (evoluzione del WEP), i quali spesso conservano la chiave di accesso di default, ossia quella fornita dal fornitore, la quale è facilmente ricavabile mediante strumenti freeware scaricabili dalla rete. Un esempio di tale attacco viene fornito in Figura 9.
2.3 DNS (Domain Name System)
Il Domain Name System, descritto nel RFC 1034-35, è un sistema utilizzato per la risoluzione di nomi di host in indirizzi IP e viceversa. Si pensi al caso di utilizzo di una rubrica telefonica rispetto all’immissione diretta del numero di telefono. Il servizio è realizzato tramite un database distribuito, costituito dai server DNS. Un nome di dominio è costituito da una serie di stringhe separate da punti, ad esempio webmail.rete.arma.carabinieri.it.
A differenza degli indirizzi IP, dove la parte più importante del numero è la prima partendo da sinistra, in un nome DNS la parte più importante è la prima partendo da destra(14).
Questa è detta dominio di primo livello (o TLD, Top Level Domain), per esempio .org o .it, i quali hanno caratterizzazione di tipo geografico o sono legati a particolari finalità di utilizzo (".com" per i servizi commerciali, ".edu" per le università americane, ".org" per le organizzazioni, ecc.). La loro gestione è assegnata a enti di diversa natura. Il NIC(15) è la Registration Authority italiana. Un dominio di secondo livello consiste in due parti, per esempio carabinieri.it, e così via. Quando un dominio di secondo livello viene registrato all’assegnatario, questo è autorizzato a usare i nomi di dominio relativi ai successivi livelli come concorsi.carabinieri.it (dominio di terzo livello) e così via. In Figura 10, viene riportato un esempio di gerarchia DNS, ogni ramo si può suddividere in differenti sottorami. Il livello di ramificazione raggiungibile non è imposto a priori.
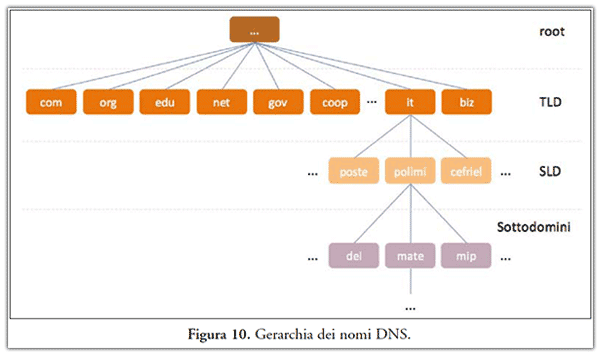
Il servizio DNS ricopre un ruolo fondamentale nella raccolta d’informazioni riguardanti un sistema connesso ad Internet, infatti è possibile, dato un indirizzo IP pubblico, risalire al nome di dominio e da questo ad una considerevole quantità di informazioni correlate. Come si vedrà nel paragrafo 3, tali informazioni svolgono un ruolo fondamentale nella ricostruzione di una attività illecita.
2.4 I file di log
Log in inglese significa tronco di legno; nel gergo nautico del 1700 era il pezzo di legno fissato ad una fune con nodi a distanza regolare, lanciato in mare e lasciato galleggiare. Il numero di nodi fuori bordo, entro un intervallo fisso di tempo indicava, approssimativamente la velocità della nave (da qui la convenzione di indicare la velocità di una nave in nodi).
Il logbook (1800) era il registro di navigazione, presente in ogni nave, su cui veniva segnata, ad intervalli regolari la velocità, il tempo, la forza del vento, oltre a eventi significativi che accadevano durante la navigazione. Con il significato di giornale di bordo, o semplicemente giornale, su cui vengono registrati gli eventi in ordine cronologico il termine è stato importato nell’informatica (1963) per indicare:
- la registrazione cronologica delle operazioni man mano che vengono eseguite;
- il file su cui tali registrazioni sono memorizzate.
Oggi è un termine universalmente accettato con questo significato di base, con tutte le sfumature necessarie nel contesto specifico. Unito al termine web (web-log) indica un diario, appunto una registrazione cronologica, in rete(16).
L’analisi di tali file di log consente quindi di stabilire se(17):
- un determinato utente in un particolare giorno ed ora si è collegato alla rete tramite un provider;
- data ed ora della sessione di navigazione;
- quale indirizzo IP temporaneo ha avuto in assegnazione per la durata della connessione;
- l’indirizzo IP utilizzato per la sessione di navigazione;
- quali informazioni (strutturate in "pacchetti") ha inviato o ricevuto per mezzo dell’indirizzo IP assegnato (accessi ai siti, scaricamento di pagine web o di specifici file, conversazioni in chat, partecipazioni a newsgroup, trasmissione o ricezione di posta elettronica).
- anagrafica dell’intestatario di un contratto di utenza Intenet (residenziale o business).
L’acquisizione e la comprensione dei dati in esso contenuti, serve per determinare la fattispecie di reato o in alcune situazioni particolari, può anche essere indispensabile per il proseguo dell’attività d’indagine stessa.
Nonostante l’esistenza di una RFC 3164, ogni ISP ha un proprio modo di fornire i dati richiesti in funzione del tipo di servizio ed all’organizzazione della propria azienda. Tale elemento ci permette dedurre subito che non esiste uno standard per i file di log, il cui contenuto quindi varierà quindi da gestore a gestore. A titolo d’esempio si confrontino Figura 11 e Figura 12 rispettivamente file di log dell’ISP Telecom e Fastweb.


L’obbligo di conservazione dei file di log (data retention) è previsto esclusivamente in capo ai fornitori di servizi di comunicazione elettronica accessibili al pubblico su reti pubbliche di comunicazione (art. 132 del D.lgs. 196/2003 come modificato dalla l. 48/2008 e dal D.Lgs. 109/2008), i quali possono essere acquisiti solo con decreto motivato del Giudice o istanza del Pubblico Ministero o del difensore, indipendentemente dal tipo di reato.
Non sono soggetti agli obblighi di data retention(18):
- i soggetti che offrono direttamente servizi di comunicazione elettronica a gruppi delimitati di persone (come, a titolo esemplificativo, i soggetti pubblici o privati che consentono soltanto a propri dipendenti o collaboratori di effettuare comunicazioni telefoniche o telematiche);
- i soggetti che, pur offrendo servizi di comunicazione elettronica accessibili al pubblico, non generano o trattano direttamente i relativi dati di traffico;
- i titolari ed i gestori pubblici o di circoli privati di qualsiasi specie che si limitano a porre a disposizione del pubblico, di clienti o soci apparecchi terminali utilizzabili per le comunicazioni, anche telematiche, ovvero punti di accesso a Internet utilizzando tecnologie senza fili, esclusi i telefoni pubblici a pagamento abilitati esclusivamente alla telefonia vocale;
- i gestori di siti Internet che diffondono contenuti sulla rete, i c.d. content provider;
- i gestori di motori di ricerca.
Gli attuali obblighi di data retention disciplinati dall’art. 132 del D.lgs. 196/2003 sono i seguenti:
- i dati relativi al traffico telefonico (diversi da quelli trattati a fini di fatturazione) devono essere conservati dal fornitore per 24 mesi dalla data della comunicazione, per finalità di accertamento e repressione dei reati; per le medesime finalità, i dati relativi al traffico telematico, esclusi i contenuti delle comunicazioni, devono essere conservati dal fornitore per 12 mesi dalla data della comunicazione (art. 132 co. 1, D.lgs 196/2003);
- i dati delle chiamate senza risposta (prima assoggettati alla medesima disciplina di cui al punto 1), che siano trattati temporaneamente da parte dei fornitori di servizi di comunicazione elettronica accessibili al pubblico oppure di una rete pubblica di comunicazione, devono essere conservati per 30 giorni (art. 132 co. 1 bis, D.lgs. 196/2003);
In definitiva grazie ai file di log, se presenti ed acquisiti nei 12 mesi dal fatto costituente reato, è possibile fornire elementi utili all’individuazione dell’"utente" registrato da un provider, ovvero l’utenza telefonica residenziale o business utilizzata per la connessione oggetto d’indagine.
Come per le registrazioni dei nomi a dominio, anche qui il sistema legislativo italiano riserva delle sorprese per gli investigatori, infatti, questi non prevede alcun obbligo di identificazione sicura e certificata del soggetto che stipula un contratto o che comunque di fatto inizia un rapporto con un Provider, cosicché saranno frequenti i casi in cui al provider l’utente fornisca dati falsi ovvero di fantasia.
2.4.1 La responsabilità degli utenti(19)
Sulla base delle considerazioni fin’ora esposta, sorge naturale porsi il problema in merito alla responsabilità dei fornitori di accesso alla Rete per le condotte assunte dai propri clienti. A tal proposito si consideri che in Italia è possibile rispondere di un reato commesso da altri solo se si aveva l’obbligo giuridico di evitarlo. A titolo di esempio, consideriamo un’analogia con il mondo reale. Poste Italiane non risponderà mai di strage per aver consegnato un plico esplosivo, diversamente ne risponderà se non avesse adottato dei provvedimenti urgenti nel caso di una segnalazione di pericolosità del pacco.
A svincolare dalla responsabilità degli ISP nei confronti delle condotte assunte in Rete dai propri clienti, è la stessa legge sulla Privacy, la quale impedisce la memorizzazione e quindi l’analisi del contenuto della navigazione di ciascun utente, in quanto, diversamente si commetterebbe un’attività d’intercettazione fraudolenta di sistemi informatici e telematici (ex art. 617-quater c.p.)(20).
Analoga posizione l’assume il responsabile dei sistemi informativi che gestisce una LAN aziendale, o lo stesso proprietario di una rete Wi-Fi domestica, il quale non ha il diritto di controllare il contenuto della navigazione di ciascuno degli utenti autorizzati ad usufruire della propria rete.
3. L’attività investigativa
Vediamo in questo paragrafo quali sono i passi che dovrà seguire un investigatore che vuole individuare il presunto autore del reato informatico, ipotizzando in primis un contesto in cui questi non abbia utilizzato tecniche di occultamento della propria identità, in seguito meglio descritte al paragrafo 5, e che la pagina web a cui ci si riferisce nell’URL citata in denuncia non è più disponibile. In caso contrario si dovrà procedere ad un repertamento della o delle pagine web rilevanti ai fini del proseguimento delle indagini, la cui complessità della procedura proposta verrà meglio illustrata nel paragrafo 4.
3.1 L’individuazione del responsabile del dominio
Riguardo il contenuto della denuncia presentata al paragrafo 2, possiamo sicuramente asserire che il primo passaggio da effettuare è quello della verifica dell’effettiva esistenza dell’URL (si veda par.2.1). Per ottenere tale risultato, l’investigatore può usufruire del protocollo WhoIs presente in Internet. Questi consente, mediante l’interrogazione (c.d. query) di appositi database, di stabilire a quale Internet Service Provider appartenga un determinato indirizzo IP (si veda par.2.2) o uno specifico DNS(21)(si veda par.2.3), nonché ottenere informazioni sulle persone fisiche o giuridiche che lo gestiscono.
3.1.1 Il protocollo WhoIs
Whois si può consultare tradizionalmente da riga di comando anche se ora esistono numerosi strumenti web-based per consultare dai database i dettagli sui diritti di proprietà dei domini(22). A titolo di esempio si veda Figura 13 e Figura 14.
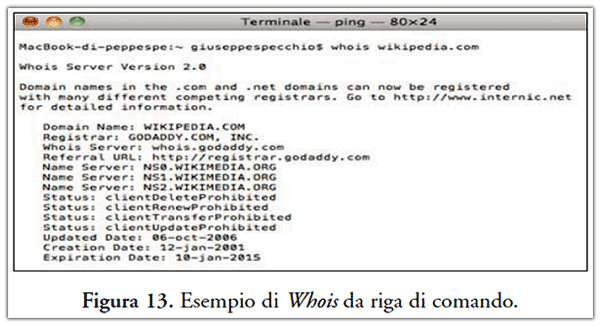

Anche in questo tipo di accertamento non dobbiamo meravigliarci se l’investigatore s’imbatterà in informazioni di carattere mendace. Basti pensare che fino a poco tempo fa in Italia per registrare un nome a dominio .it era previsto l’uso di un fax da inviare Istituto di Informatica e Telematica - CNR(23). Risulterà facilmente intuibile che tale tipo di procedura risulta essere poco sicura dal punto di vista della genuinità dei dati trasmessi, in quanto l’invio della fotocopia di un documento è facilmente falsificabile. Vedremo in seguito che tale tecnica verrà utilizzata anche per altri servizi d’identificazione. Come si è visto, grazie a tale accertamento l’investigatore è riuscito a sapere qual è il nominativo del responsabile della gestione del sito e dove sono dislocati i server. Nel caso in esame, il cui report viene raffigurato in Figura 14, l’URL http://www.youtube.com/watch?v=ErdZLgRsn1U viene gestita da Google Inc., la cui sede è Amphitheatre Parkway Mountain View CA 94043 US, e pertanto per continuare la sua indagine l’investigatore non dovrà fare altro che informare (ex art. 347 c.p.p.) l’Autorità Giudiziaria (in seguito A.G.) ed evidenziare che il proseguimento dell’indagine è legata ad un’eventuale condizione di procedibilità della Rogatoria Internazionale (ex. art. 723 c.p.p.).
3.2 L’individuazione del locus commissi delicti
Una volta stilata la Comunicazione di Notizia di Reato, l’investigatore si trova di fronte ad uno dei dilemmi che caratterizzano le indagini in materia di criminalità informatica, ovvero l’individuazione dell’A.G. competente per le indagini. In generale, in base all’art. 6 c.p. è prevista la punibilità per chiunque commetta un reato nel territorio dello Stato, anche se la condotta (azione od omissione) si sia tenuta solo in parte. Nell’ambito della legislazione penale ordinaria, unica deroga a tale regola vale solo per la condotta che viola l’art. 604 c.p., ossia delitti contro la prostituzione e la pornografia minorile, e contro la libertà sessuale.
Quindi nel caso in esame, ossia una diffamazione immessa in rete, si potrà considerare consumata non solo nel luogo ove questa viene percepita dalla presunta parte offesa, ma anche, nel luogo in cui viene immessa in rete. In merito a tale problematica, di seguito viene fornito uno stralcio della sentenza n. 4741 del 27 dicembre 2000 della V sezione della Corte di Cassazione Penale:
«la possibilità di dare applicazione alla legge penale italiana dipende essenzialmente dalla concreta formulazione delle singole norme incriminatrici, strutturate, di volta in volta, come reati commissivi od omissivi, di danno o di pericolo, di pura condotta o di evento, ecc. La diffamazione … è un reato di evento, inteso quest’ultimo come avvenimento esterno all’agente e causalmente collegato al comportamento di costui. Si tratta di evento non fisico, ma per così dire psicologico, consistente nella percezione da parte del terzo (rectius dei terzi) della espressione offensiva … in realtà la percezione è atto non certamente ascrivibile all’agente, ma a soggetto diverso, anche se - senza dubbio - essa è conseguenza dell’operato dell’agente. Il reato, dunque, si consuma non al momento della diffusione del messaggio offensivo, ma al momento della percezione dello stesso da parte di soggetti che siano "terzi" rispetto all’agente ed alla persona offesa … Per di più, nel caso in cui l’offesa venga arrecata tramite Internet, l’evento appare temporalmente, oltre che concettualmente, ben differenziato dalla condotta. Ed invero, in un primo momento, si avrà l’inserimento "in rete", da parte dell’agente, degli scritti offensivi e/o delle immagini denigratorie, e, solo in un secondo momento (a distanza di secondi, minuti, ore, giorni ecc.), i terzi, connettendosi con il "sito" e percependo il messaggio, consentiranno la verificazione dell’evento. Tanto ciò è vero che nel caso in esame sono ben immaginabili sia il tentativo (l’evento non si verifica perché, in ipotesi, per una qualsiasi ragione, nessuno "visita" quel "sito"), sia il reato impossibile (l’azione è inidonea, perché, ad esempio, l’agente fa uso di uno strumento difettoso, che solo apparentemente gli consente l’accesso ad uno spazio web, mentre in realtà il suo messaggio non è mai stato immesso "in rete"). Orbene, l’art. 6 c.p., al comma secondo, stabilisce che il reato si considera commesso nel territorio dello Stato, quando su di esso si sia verificato, in tutto, ma anche in parte, l’azione o l’omissione, ovvero l’evento che ne sia conseguenza. La c.d. teoria della ubiquità, dunque, consente al giudice italiano di conoscere del fatto-reato, tanto nel caso in cui sul territorio nazionale si sia verificata la condotta, quanto in quello in cui su di esso si sia verificato l’evento. Pertanto, nel caso di un iter criminis iniziato all’estero e conclusosi (con l’evento) nel nostro paese, sussiste la potestà punitiva dello Stato italiano».
Tale dottrina è stata ulteriormente raffinata nel tempo con ben due sentenze:
- sentenza del 21 giugno 2006, n. 25875 emessa dalla Corte di Cassazione Penale, sez. 5: «La diffamazione, che è reato di evento, si consuma nel momento e nel luogo in cui i terzi percepiscono l’espressione ingiuriosa e dunque, nel caso in cui frasi o immagini lesive siano state immesse sul web, nel momento in cui il collegamento viene attivato».
La Corte, proprio con riferimento a un caso di "diffamazione telematica", ebbe ad affermare che la diffamazione, in quanto reato di evento, si consuma nel momento e nel luogo in cui i terzi percepiscono la espressione ingiuriosa e dunque, nel caso in cui frasi o immagini lesive siano state immesse sul web, nel momento in cui il collegamento viene attivato;
- sentenza 5 febbraio 2009 (dep. 25 febbraio 2009), n. 8513/2009 emessa dalla Corte di Cassazione Penale, sez. I, la quale asseriva che: «La diffamazione telematica si consuma nel momento e nel luogo in cui i terzi percepiscono l’espressione ingiuriosa, che, nel caso in cui le frasi offensive siano state immesse sul web, sono quelli in cui il collegamento viene attivato. Ove detto luogo non sia individuabile, deve farsi ricorso ai criteri suppletivi di cui all’art. 9 c.p.p. Ed in tal senso, a norma del comma 2 di detto articolo, la competenza va attribuito al giudice della residenza dell’imputato, non essendo noto il luogo indicato nel comma 1, vale a dire l’ultimo luogo in cui è avvenuta una parte dell’azione o dell’omissione».
Per quanto riguarda i reati di prostituzione minorile e reati informatici propri, è stata istituita una distrettualizzazione delle competenze grazie alla legge 18 marzo 2008 n. 48, la quale con l’art. 11 ha modificato il testo dell’art. 51 c.p.p. aggiungendo il comma 3-quinquies, definendo che quando si tratta di procedimenti per i delitti, consumati o tentati, di cui agli articoli:
- 600-bis (Prostituzione minorile);
- 600-ter (Pornografia minorile);
- 600-quater e 600-quater.bis (Detenzione di materiale pornografico);
- 600-quinquies (Iniziative turistiche volte allo sfruttamento della prostituzione minorile.);
- 615-ter (Accesso abusivo ad un sistema informatico o telematico);
- 615-quater (Detenzione e diffusione abusiva di codici di accesso a sistemi informatici o telematici);
- 615-quinquies (Diffusione di apparecchiature, dispositivi o programmi informatici diretti a danneggiare o interrompere un sistema informatico o telematico);
- 617-bis (Installazione di apparecchiature atte ad intercettare od impedire comunicazioni o conversazioni telegrafiche o telefoniche);
- 617-ter (Falsificazione, alterazione o soppressione del contenuto di comunicazioni o conversazioni telegrafiche o telefoniche);
- 617-quater (Intercettazione, impedimento o interruzione illecita di comunicazioni informatiche o telematiche);
- 617-quinquies (Installazione di apparecchiature atte ad intercettare, impedire o interrompere comunicazioni informatiche o telematiche);
- 617-sexies (Falsificazione, alterazione o soppressione del contenuto di comunicazioni informatiche o telematiche);
- 635-bis (Danneggiamento di informazioni, dati e programmi informatici);
- 635-ter (Danneggiamento di informazioni, dati e programmi informatici utilizzati dallo Stato o da altro ente pubblico o comunque di pubblica utilità);
- 635-quater (Danneggiamento di sistemi informatici o telematici);
- 640-ter (Frode informatica);
- 640-quinquies (Frode informatica del soggetto che presta servizi di certificazione di firma elettronica);
del codice penale, le funzioni indicate nel comma 1, lettera a), del presente articolo sono attribuite all’ufficio del pubblico ministero presso il tribunale del capoluogo del distretto nel cui ambito ha sede il giudice competente. In generale comunque, quando non è ancora possibile determinare la competenza per territorio secondo le regole innanzi descritte, è possibile far ricorso al criterio sussidiario sancito dall’art. 9 c.p.p., cioè è decisivo il luogo ove fu eseguito l’arresto, emesso un mandato o decreto di citazione ovvero il luogo in cui fu compiuto il primo atto del procedimento.
3.3 A decreto acquisito
Una volta ottenuta l’autorizzazione allo svolgimento degli accertamenti telematici da parte del Pubblico Ministero, l’investigatore dovrà contattare il fornitore di servizi individuato con il servizio di WhoIs precedentemente illustrato.
Fino a quanto esposto tutto sembra chiaro, in realtà i provider il più delle volte sono all’estero e laddove siano presenti accordi di rogatoria internazionale, questi la necessitano nella richiesta, la cui modalità di comunicazione varia da paese a paese. Fortunatamente, Content Provider(24) come Google e Yahoo, agevolano il lavoro delle forze dell’ordine purché ci sia personale accreditato presso i loro database con cui interloquire. In generale, l’operatore durante la formulazione della richiesta dovrà formulare, il più delle volte in lingua inglese laddove non ci sia un ufficio legale in Italia, precisamente la tipologia di eventi d’interesse per le indagini, corredando la stessa URL, nickname, email, data, ora o quant’altro utile alla ricostruzione dell’evento da cui ricavare il relativo IP associato. In Figura 15 viene fornito un esempio di richiesta di accertamenti alla società Google Inc., quale gestore di YouTube.com.

3.4 La riposta del provider
La risposta del Content Provider, in generale conterrà le seguenti informazioni, indipendentemente dalla presenza o meno della risorsa d’interesse per le indagini:
- data ed ora dell’evento, ad esempio November 23 2008, 06:22 AM PDT;
- Id operazione, generalmente un codice che identifica in maniera univoca l’operazione svolta all’interno di quel portale;
- IP del client che ha effettuato le operazioni, ad esempio 213.205.21.209;
- URL della risorsa d’interesse, a conferma di quella segnalata, cioè http://www.youtube.com/watch?v=ErdZLgRsn1U;
- Username utilizzata per creare e modificare il video o messaggio, ad esempio "ombra";
- I dati personali inseriti al momento della registrazione al sito;
- Email indispensabile per la creazione e la modifica dell’account, ad esempio aspide@yahoo.com;
- IP, data ed ora relative all’attivazione dell’account, ad esempio 85.18.227.247.
A tal proposito si tenga presente che il più delle volte i server non sono su territorio italiano, o comunque non hanno un orario impostato sul nostro fuso orario(25), quindi sarà accortezza dell’investigatore chiedere in sede di richiesta di far specificare la tipologia di fuso orario. Nella fattispecie in esame, ad esempio, la data e l’ora dell’evento era espressa secondo il fuso orario della costa del pacifico, quindi il periodo November 23 2008, 06:22 AM PDT è riconducibile al 23 novembre 2008, 03:22 PM CET (UTG+1)(26).
Data ed ora, unitamente all’ID dell’operazione probabilmente saranno gli unici dati da ritenere subito attendibili, in quanto, come vedremo anche in seguito, tutti gli altri sono facilmente alterabili o comunque non attendibili, poiché sono informazioni fornite dal client e non definite dalla macchina server. A tal proposito si evidenzia che elementi come username, email, e dati personali non sono in corrispondenza biunivoca con l’utente, il quale il più delle volte usa dati di fantasia.
3.5 L’attività di tracciamento
Sulla base delle informazioni ricevute al punto precedente, l’investigatore agendo anche d’iniziativa, può censire da quale fornitore di servizi è gestito l’indirizzo o gli indirizzi IP d’interesse per il proseguimento delle indagini. Per far ciò, procederà come già illustrato all’inizio di questo paragrafo, ovvero tramite un servizio di Whois. Un esempio d’esito di tale accertamento viene riportato in Figura 16.
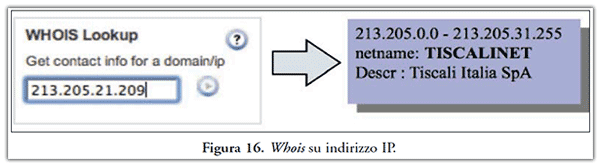
L’investigatore in questo caso è stato fortunato, in quanto l’Autonomous System(27) (in seguito solo AS) si trova in Italia, quindi potrà effettuare una richiesta all’Autorità Giudiziaria per accedere ai file di log gestiti dalla società Tiscali Net S.p.A. Come già anticipato al paragrafo 2.4, l’investigatore in sede di comunicazione all’A.G., dovrà ben evidenziare l’ordine di priorità dell’attività tecnica da svolgere, accertando i limiti di data retention stabiliti dall’ex. art. 132 d.lgs. 196/2003, cioè massimo 12 mesi. Così facendo si eviterà un’inutile risposta negativa da parte del fornitore di servizi. Nel caso in esame, il periodo da considerare non va contemplato ovviamente dal momento della presentazione della querela, il quale inficia solo sulla condizione di procedibilità, ma sulla data di pubblicazione della risorsa web incriminata. Tale data, la si evince dalla risposta del Content Provider, nel nostro caso Google Inc. il quale ha comunicato che il video era stato pubblicato il 23 novembre 2008, 03:22 PM CET (UTG+1). Quindi nel caso in cui non siano passati più di 12 mesi dall’evento in esame, l’investigatore si troverà di fronte ad un vincolo di non procedibilità tecnica, ossia della cancellazione dei file di log.
3.6 Alla ricerca dell’indiziato
Ipotiziamo che la società Tiscali Net S.p.A., risponda che in data 23 novembre 2008 alle ore 15:22, l’IP dinamico 213.205.21.209 era assegnato a tale Sig. Verdi Luca, residente a Roma in Piazza Venezia n. 1, intestatario del contratto d’utenza residenziale o business 06/1234567.
A tal punto, i più penseranno di aver identificato il potenziale reo, ma a tal proposito si consideri che:
- l’IP associato all’utenza residenziale o business, potrebbe essere gestito da un Internet Point, i cui titolari sono soventi non identificare i propri clienti, o che gli stessi abbiano presentato documenti falsificati o del tutto falsi e che comunque non possono conservare e verificare il traffico effettuato dai propri clienti;
- l’intestatario dell’utenza potrebbe:
• essere deceduto ed i dati del contratto di servizio telefonico non sono stati aggiornati;
• non aver adottato misure minime di sicurezza per la propria rete Wi-Fi;
• essere convivente estraneo al nucleo familiare, caratterizzato da un minore non imputabile;
- etc. l’accesso alla risorsa incriminata potrebbe avvenire da un dispositivo mobile, la cui utenza potrebbe essere associata ad un individuo che abbia fornito dati mendaci al momento della stipula del contratto con il proprio ISP, o che comunque non risieda in Italia;
Tali eventi si verificano di frequente poiché il sistema italiano allo stato attuale non prevede alcun obbligo di identificazione sicura del soggetto che stipula un contratto o che comunque di fatto inizia un rapporto con un Provider(28).
Un esempio di tale problematica viene rappresentata in Figura 17.

Quindi un bravo investigatore in prima istanza, già prima di informare l’A.G. potrà verificare l’effettiva esistenza in vita dell’indiziato, nonché la sua presenza sul territorio nazionale, per poi richiedere una perquisizione seguita da accertamenti telematici. Laddove il potenziale l’indiziato fosse un minore, si consiglia di acquisire i nominativi dei propri familiari o conviventi potenziali intestatari dei contratti stilati con gli ISP.
Sulla base di tali considerazioni operative, risulta ragionevole considerare che laddove si fosse giunti ad un IP associato all’ultimo miglio, ovvero associato ad un’utenza residenziale o business veritiera, in cui il titolare del contratto abbia fornito dati non mendaci, bisogna proseguire l’attività di analisi anche sulle macchine a disposizione della parte. Tale operazione risulta necessaria, poiché il solo IP non è considerato condizione sufficiente per l’identificazione della controparte, in quando per avere una buona tesi accusatoria bisogna dimostrane la disponibilità univoca della o della macchine in suo possesso. Basti pensare che in presenza di un’infrastruttura di rete IEEE 802.3 - ISO 8802.3, l’assegnazione degli indirizzi IP non è considerata vincolante, in quanto è sempre possibile modificare l’indirizzo di rete della propria postazione, utilizzandone uno differente da quello assegnato, oppure utilizzando l’indirizzo di un nodo momentaneamente spento, o addirittura utilizzando un indirizzo contemporaneamente in uso e con ciò generando un conflitto d’indirizzamento.
A supporto di tale tesi si è espressa anche la V Sezione Penale in composizione monocratica del Tribunale di Roma, il quale con la sentenza 22205/09 del 20 novembre 2009, depositata il 22 dicembre 2009, si è espressa in merito ad una vicenda in cui all’imputato era stato contestato di aver immesso sulla rete Internet un annuncio diffamatorio nei confronti della persona offesa, facendolo apparire a lei stessa riconducibile ed aggiungendo l’indirizzo di posta elettronica e il numero di telefono cellulare della medesima. Nella fattispecie, il tribunale capitolino sanciva che:
«Pur a fronte di una ricostruzione dibattimentale che ha dimostrato il rapporto di conoscenza e di amicizia intercorrente tra l’imputato e la persona offesa, poiché con un collegamento ADSL Wi-Fi senza protezione (circostanza non verificata dalla P.G. nel corso delle indagini ma emersa dalla complessiva istruttoria dibattimentale in relazione ai fatti contestati) chiunque può utilizzare un computer per mandare messaggi in Internet aventi IP riconducibili alla medesima connessione, non può dirsi raggiunta la prova, oltre ogni ragionevole dubbio, di un invio da parte dell’imputato in assenza dell’analisi del computer da lui utilizzato».
Nel caso venisse identificata l’utenza residenziale o business tramite la quale si sospetta che sia stata posta in essere la condotta antigiuridica, l’Ufficiale di Polizia Giudiziaria che interviene sulla scena del crimine, procederà ad una perquisizione telematica in modo tale da ricercare i dati d’interesse per le indagini, i quali dovranno essere successivamente sequestrati. Le caratteristiche di tale fase esulano dall’obiettivo di tale articolo. Per un approfondimento in merito si consiglia la lettura del MemberBook IISFA 2011 (www.iisfa.it).
4. Il repertamento della pagina web
Come è stato anticipato al paragrafo 3, una delle attività salienti di un’indagine in Internet è il repertamento di una o più pagine web. Tale operazione risulta essere tempo/macchina dipendente, in quanto trattandosi di risorse non immediatamente disponibili, ossia presenti su macchine remote, bisogna che da un lato ci sia un ente terzo indipendente che certifichi e quindi sincronizzi il tempo dell’accertamento, mentre dall’altro lato c’è che i dati acquisiti saranno vincolati sia dall’user agent che dalla configurazione del sistema operativo utilizzato per il repertamento. A operazioni ultimate, tali dati per essere considerati elementi di prova, dovranno essere validati nella loro integrità, tramite il calcolo di un doppio codice hash, e possibilmente resi non ripudiabili apponendo una firma digitale.
4.1 Preparare l’ambiente di lavoro
Il primo passo da realizzare è l’avvio di una sonda sulla macchina client, la quale acquisisca e consenta ad operazioni ultimate di analizzare il traffico di rete. Tale ruolo verrà ricoperto da uno sniffer(29) di rete come ad esempio WireShark(30).
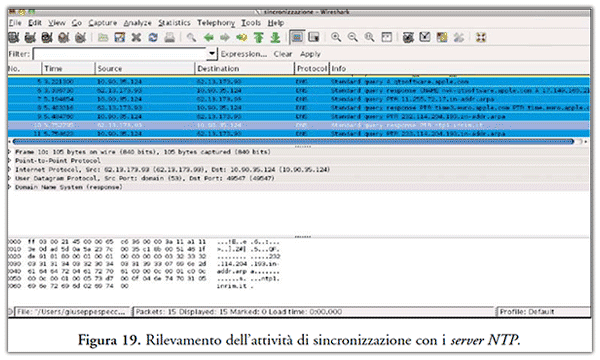
Una volta avviata la sonda attiveremo il processo di sincronizzazione dell’orologio di sistema con un ente terzo certificato, in modo tale da ottenere una marcatura temporale. Tale risultato lo si può ottenere sia dalle impostazioni di sistema dell’oramai quasi totalità dei moderni sistemi operativi, che da software di terze parti, come ad esempio il servizio gratuito presente sui server NTP(31) dell’I.N.RI.M.(32), di cui un esempio di esecuzione viene fornito in Figura 18.

Tracce relative a tale operazione potranno essere verificate anche in sede di accertamento in post mortem, analizzando il contenuto del file .pcap ottenuto dalla sonda sniffer, come riportato in Figura 19.
4.2 Il repertamento
Oggetto d’indagine può essere una sola pagina, come ad esempio un caso di diffamazione, o più pagine, fine a ricoprire un intero sito, come nel caso di pedopornografia.
Procedendo in maniera induttiva partiremo dal caso banale, ossia il caso di una sola pagina, per poi passare all’acquisizione di un intero sito. Prima però di procedere al mero aspetto tecnico, si consideri che il modello ideale di acquisizione di una pagina web prevede che sia prelevata la singola risorsa presente sul server, la quale dovrà essere messa a disposizione dell’analista per gli accertamenti del caso, ma spesso tale operazione non risulta possibile per i seguenti motivi:
- presenza della pagina su server in territorio extra-nazionale;
- file rientranti nell’elenco di configurazione robots.txt, ossia il dispositivo che contiene le regole utilizzate dai crawler (detti anche spider) per applicare restrizioni di analisi sulle pagine di un sito Internet;
- la pagina viene realizzata al momento della consultazione, poiché risultato dell’elaborazione di una c.d. pagina web dinamica (script PHP, Perl, Jsp);
- impossibilità di accedere alla pagina tramite canali terzi (FTP, SSH, fisicamente).
In virtù di tali vincoli, ancora tutt’oggi vengono formulate deleghe d’indagine basate su una semplice stampa di una pagina web, la quale nulla ha che fare con quanta sancito dal Codice dell’Amministrazione Digitale (D.lgs. n. 82/ 2005 e successive modifiche). L’art. 1 lett. p, sancisce infatti che un documento informatico è "la rappresentazione informatica di atti, fatti o dati giuridicamente rilevanti", ma:
- se non è sottoscritto con una firma elettronica (art. 1 lett. q), non può avere alcuna efficacia probatoria, ma può al limite, a discrezione del Giudice, soddisfare il requisito legale della forma scritta (art. 20 co. 1 bis);
- anche quando sia firmato con una firma elettronica "semplice" (cioè non qualificata, come ad esempio la PGP) può non avere efficacia probatoria, in tal caso il giudice dovrà infatti tener conto, per attribuire tale efficacia, delle caratteristiche oggettive di qualità relative a riservatezza ed integrità del documento informatico.
Quindi sulla base di tali considerazioni legali, un documento informatico che abbia la c.d. "firma elettronica semplice" è un documento che sarà valutato liberamente dal giudice potendo avere solo efficacia di scrittura privata, mentre su un altro piano sarà quello sottoscritto con una "firma digitale qualificata", ovvero tutte quella C.A. registrate ed autorizzate dal CNIPA (es. Poste Italiane).
Risulta ovvio che tali vincoli probatori vincolano soprattutto quei soggetti i quali non ricoprono la veste di Pubblico Ufficiale (ex art. 357 c.p.), come ad esempio i consulenti di accusa o difesa o periti. Nel caso in cui tale attività venga svolta ad esempio da un Ufficiale od Agente di Polizia Giudiziaria, il suo stesso status consente già una quanto minima ma attendibile attività descrittiva (art. 354 co. 2 c.p.p., c.d. sopralluogo e per gli Agenti di P.G. art. 113 disposizioni di attuazione del c.p.p.), come ad esempio prendere nota o riprendere ciò che compare a video, assumendo così la valenza di prova documentale (art. 234 c.p.p.).
Risulta ovvio che tali attività forniranno solo informazioni basilari, spesso poco utili all’immediato proseguimento delle indagini, come ad esempio la conoscenza del server ove è fisicamente presente un video pubblicato all’interno di una pagina web.
4.2.1 L’acquisizione
Di seguito viene fornita una carrellata di tecniche possibili per l’acquisizione di una risorsa web, evidenziandone le caratteristiche e soprattutto i limiti, cosa che ci farà capire fin da subito che non esiste una tecnica esaustiva.
4.2.1.1 wget
Per l’acquisizione di una o più pagine web lo strumento più collaudato nell’ambito della comunità scientifica è sicuramente wget.
Questi è uno strumento da riga di comando Unix nato per un download non interattivo di una pagina web.
È possibile scaricarlo da http://www.gnu.org/software/wget/, ove viene fornita anche una versione per Windows(33).
La sintassi del comando è la seguente:
wget -[opzioni] [URL]
wget - proxy-user "Domain\User" - proxy-password "Password " URL
Utilizzando il comando wget con l’opzione -p non ci limiteremo a scaricare la singola pagina d’interesse ma, acquisiremo anche i relativi fogli di stile e le immagini in modo tale da poterla visualizzare correttamente in locale, come riportato in Figura 20.

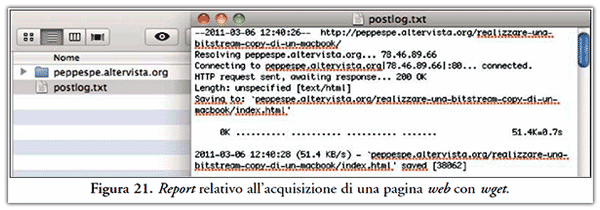
Con l’opzione -o invece ingloberemo in un unico file di testo tutto quello che ci verrebbe visualizzato a video, utilizzandolo così come report dell’accertamento. A tal proposito si veda Figura 21.
Possiamo addirittura effettuare il mirroring di tutte le risorse liberamente accessibili dal sito utilizzando l’opzione -m, agevolando la consultazione in locale dell’intero sito, trasformando i collegamenti da assoluti a relativi utilizzando l’opzione -k. In Figura 22 viene fornito un esempio.

Wget nonostante sia uno strumento estremamente flessibile non riesce a supportare tutte le innumerevoli casistiche che si possono incontrare in un’indagine forense, infatti:
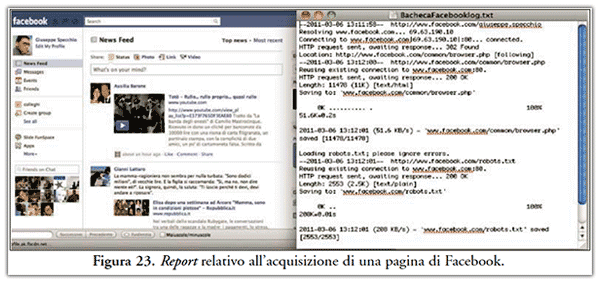
- non riesce ad acquisisce pagine il cui accesso viene gestito tramite le regole definite all’interno del file robots.txt. Ad esempio, nel caso di una pagina Facebook, come indicato in Figura 23, wget non viene riconosciuto come user agent;
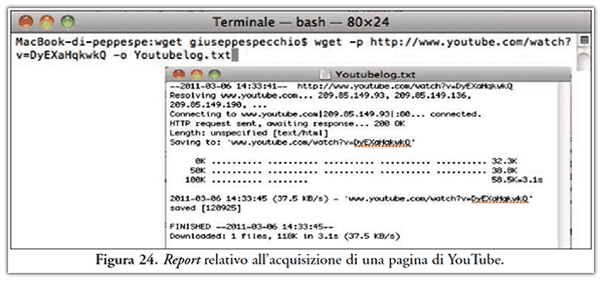
- non estrapola video da YouTube, come riportato in Figura 24;
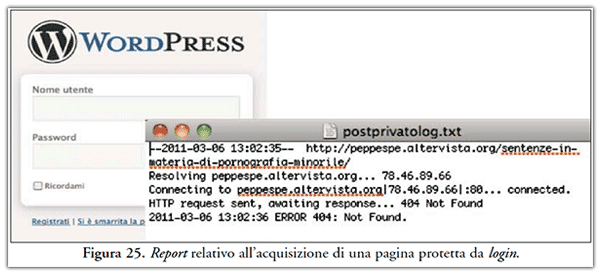
- non accede a risorse vincolate ad operazioni di login, come indicato in Figura 25.
4.2.1.2 HashBot
In quest’ultimi anni una valida alternativa al tool wget si è dimostrata la web application forense tutta italiana HashBot(34). Questi funge da sistema terzo di validazione per il contenuto di una pagina o documento nel web.
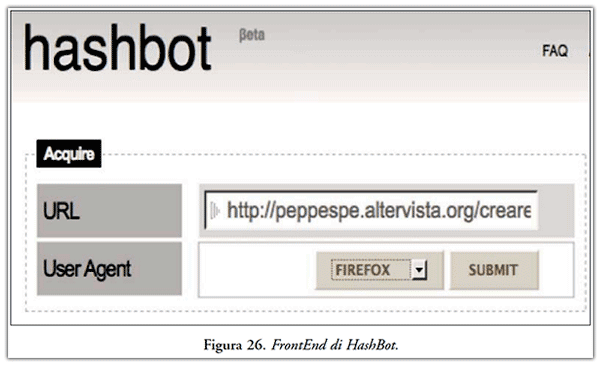
L’applicativo nostrano è diventato uno standard de facto nell’ambito della comunità forense italiana, riscuotendo il suo principale successo nell’ambito del processo Vivi Down della Procura della Repubblica di Milano nei confronti della società Google, quale responsabile del portale YouTube. L’uso di HashBot risulta molto intuitivo, infatti l’utente non deve far altro che specificare l’URL della pagina e l’user agent(35) utilizzato per la sua visualizzazione. L’interfaccia di HashBot viene fornita in Figura 26.
Una volta acquisita la pagina HashBot fornirà un report, di cui un esempio viene fornito in Figura 27, nel quale sono contenute informazioni d’interesse forense, ossia il traffico relativo alla richiesta HTTP, il file acquisito e fornito in un archivio zip, l’integrità di quest’ultimi. Le principali informazioni fornite risultano essere le seguenti:
- Header: la risposta del server alla richiesta di HashBot;
- From IP: l’indirizzo IP dell’utente che ha richiesto il processo di acquisizione;
- URL: il collegamento al documento acquisito;
- Date: data di acquisizione;
- Time: ora di acquisizione;
- Hash File: i codici hash MD5 e SHA1 del file acquisito. Ovvero l’impronta digitale univoca del file calcolata su due algoritmi;
- Hash Header: i codici hash MD5 e SHA1 delle informazioni dell’header salvate in apposito file;
- File Type: il tipo di documento scaricato dal processo di acquisizione;
- Code: codice alfanumerico creato da HashBot che deve considerarsi come ID univoco del processo di acquisizione.

All’interno del file zip fornito da HashBot troveremo i seguenti file:
- <keycode>–code.txt: file di testo contenente le informazioni di validazione ed i dati relativi al processo di acquisizione, ossia le sottosezioni "Validate Info" e "File Info" della sezione Status;
- <keycode>–headers.txt: file di testo contenente la risposta dell’header del server remoto, ossia la sottosezione "Headers Info" della sezione Status;
- <keycode>.<ext>: il file scaricato dal processo di acquisizione. Questo verrà rinominato con il codice alfanumerico identificativo del processo di acquisizione e manterrà la sua estensione se riconosciuta dal HashBot. Nel caso in cui il tipo di file non viene riconosciuto sarà usata l’estensione arbitraria unk.
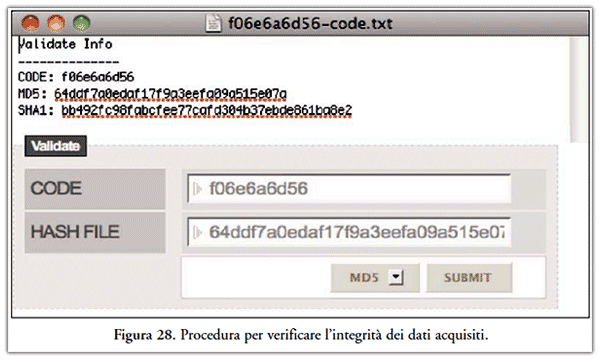
HashBot si è dimostrato un ottimo strumento di natura forense in quanto, fornisce la possibilità di verifica dell’integrità dei dati acquisiti fornendo in input il keycode ed uno dei due codici hash della pagina, come indicato in Figura 28.
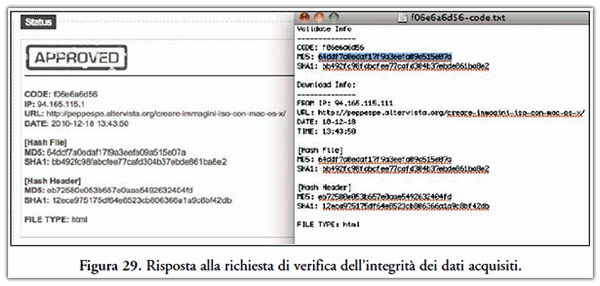
Le informazioni riportate nella risposta sono la prova che HashtBot è stato usato precedentemente per acquisire il documento di cui si sta richiedendo la validazione. Tutte le informazioni di validazione mostrate da HashBot dovranno corrispondere a quanto riportato nella sezione "Download Info" del file <keycode>–code.txt, come riportato in Figura 29.
Come tutte le nuove tecnologie anche HashBot ha dei suoi limiti:
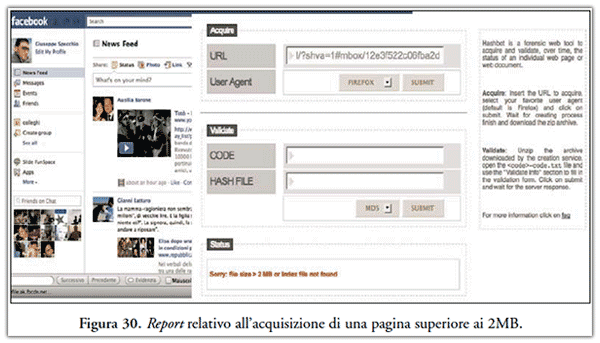
- non riesce ad acquisisce pagine superiori ai 2MB. A tal proposito si veda il tentativo di acquisizione di una bacheca Facebook riportata in Figura 30;
- estrapola il solo la pagina in formato HTML, ossia esclude gli elementi multimediali come video, immagini ed audio, rimandando alla consultazione di quest’ultimi con le rispettive URL, creando così delle serie difficoltà di analisi del documento laddove questi in un secondo momento venissero rimosse o spostate di percorso. A tal proposito si veda la Figura 31, ove viene fornito l’esito dell’acquisizione di una pagina di YouTube;
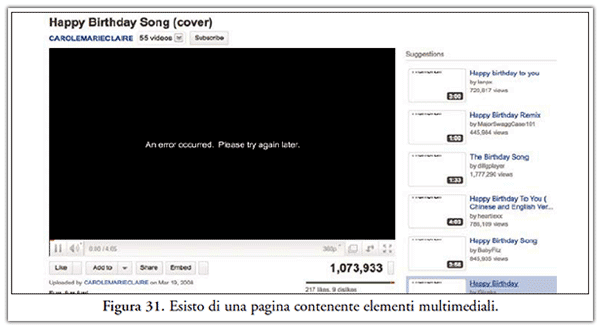
- non accede a risorse vincolate ad operazioni di login. A tal proposito si veda Figura 32, ove viene fornito l’esito dell’acquisizione di un post scritto su piattaforma wordpress e che lo stesso per essere visualizzato richiede un’operazione di riconoscimento dell’utente.
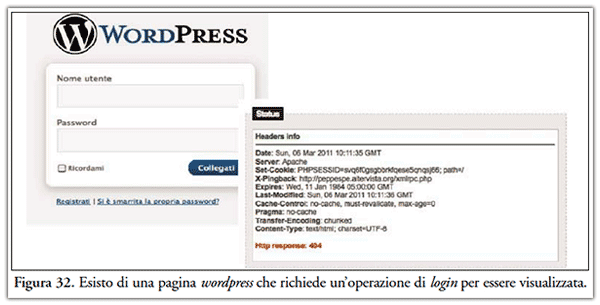
4.2.1.3 In extrema ratio
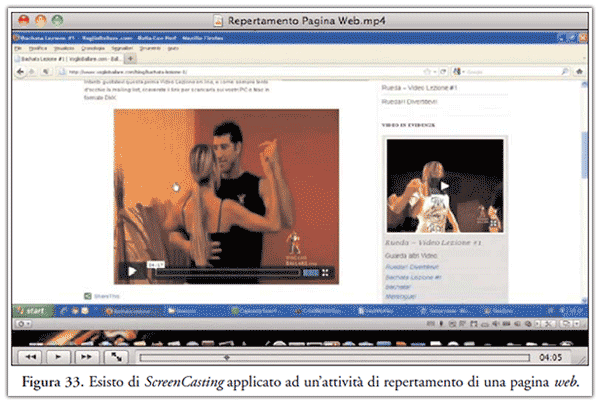
Come è stato dimostrato esistono pagine che non possono essere repertate in alcun modo, ma ai fini di giustizia c’è sempre la necessità di congelare la scena del crimine così come si presenta. Per soddisfare tale esigenza, fornendo un quanto minimo livello di integrità dei dati potremmo salvare la pagina web in formato pdf ed effettuare un’attività di videoripresa od ancor meglio di screencasting, come riportato in Figura 33, memorizzando il tutto subito su un supporto in sola lettura come ad esempio un DVD.
4.3 L’attività di analisi
L’attività di repertamento dell’intero traffico di rete che ha caratterizzato la nostra attività di acquisizione di una o più pagine web fornirà molteplici vantaggi, tra cui:
- possibilità di verifica dell’effettiva esecuzione delle attività svolte, come ad esempio la sincronizzazione od il download di una risorsa;
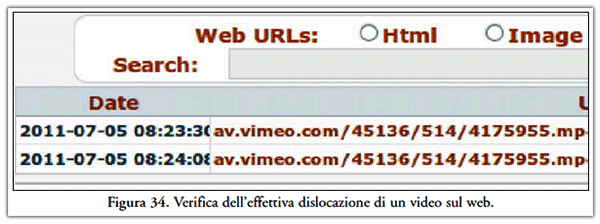
- consentirà di effettuare un’analisi approfondita della dislocazione delle risorse, come riportato in Figura 34;
- consentirà di fornire un buon livello di trasparenza del nostro il quale non potrà altro che giovare a nostro favore in sede di contraddittorio delle parti.
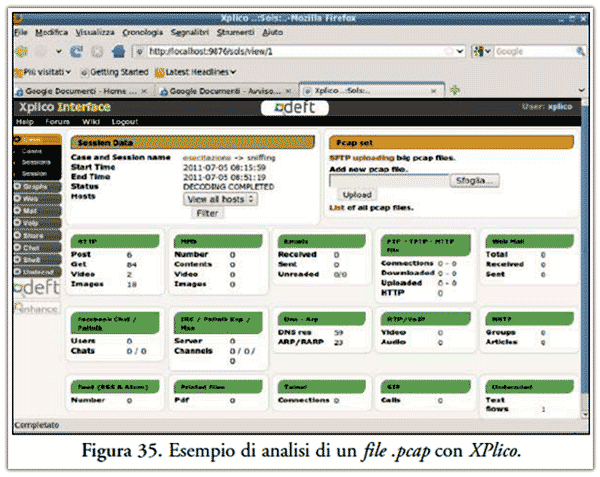
Per la realizzazione di tale fase investigativa possiamo utilizzare due ottimi strumenti, ossia Xplico(36), riportato in Figura 35 o lo stesso WireShark già illustrato in Figura 19.
5. Antiforensics
Con il termine antiforensics, s’intendono tutte quelle tecniche volte ad eludere le tecniche investigative adottate nella Digital Forensics, tra cui ricadono:
- data hiding, comprenderei crittografia e steganografia;
- distruzione dei dati, che può riguardare file o dischi interi, file già cancellati, tracce di navigazione, washing di vario tipo del sistema operativo e dei software;
- anonimato, sia nella fase di connessione sia nella fase di navigazione e altre operazioni in rete;
- corruzione o modifica di dati, metadati, immagini, pacchetti in rete;
- social engineerig, molto vicina al criminal profiling, correlata alle azioni dell’uomo.
Il mascheramento l’Indirizzo IP è quindi una strategia paragonabile all’occultamento dell’arma del delitto, o del corpo del reato (ad esempio la refurtiva). Le tecniche e gli strumenti sono numerosi e possono essere applicati in combinazione tra loro.
A titolo di esempio citiamo alcune tecniche di occultamento degli indirizzi IP, il cui utilizzo non richiedono una preparazione da provetto black hat(37) o ingenti capitali per l’acquisto di software, poiché il tutto gratuito:
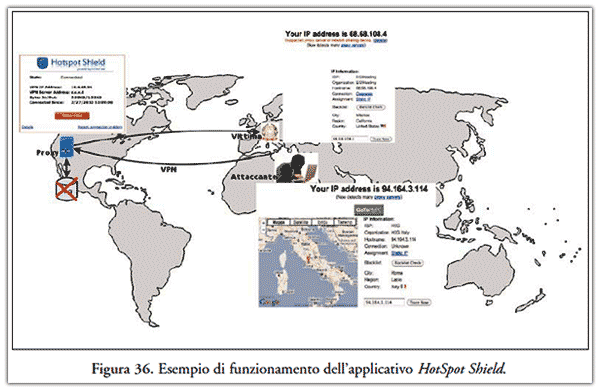
- combinazione di sistemi Virtual Private Network(38) e Proxy Server(39), così facendo l’attaccante si garantisce l’impossibilità matematica della decodifica della comunicazione tra lui ed il proxy, il quale sovente risulta essere dislocato all’estero, oltre che comportarsi come testa di ponte poiché sulla scena del crimine digitale comparirà l’IP di quest’ultimi, questi non terrà traccia dell’IP dell’attaccante.
La Figura 36 sintetizza la tecnica appena descritta;
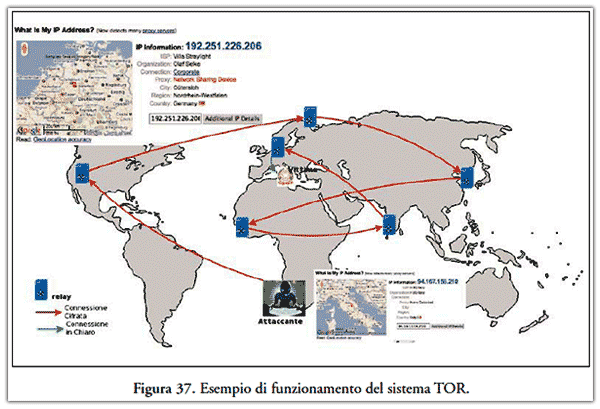
- sistema Tor (The Onion Router), esso è costituito da un numero elevato di router realizzati da volontari i quali costantemente definiscono percorsi casuali e crittografati tra i diversi hop del network; le informazioni trasmesse al suo interno dunque, non sono tracciabili e quindi risulta impossibile risalire al mittente(40).
Con tale sistema Tor impedisce a chiunque osservi la connessione di sapere quali siti si stanno visitando, ed impedisce ai siti visitati di scoprire da dove si proviene realmente, in poche parole consente di accedere ai siti con un IP reindirizzato più volte, mentre i dati della navigazione vengono criptati(41) tramite il protocollo di trasmissione Socks4, fatta eccezione per l’hop tra l’ultimo router TOR e la destinazione finale.
La Figura 37 sintetizza la tecnica appena descritta.
Anche se la funzionalità più popolare di Tor è quella di fornire anonimità ai client, può anche fornire anonimità ai server. Usando la rete Tor, è possibile ospitare dei server in modo che la loro localizzazione nella rete sia sconosciuta. Un servizio nascosto può essere ospitato da qualsiasi nodo della rete Tor, non importa che esso sia un relay (così vengono chiamati i nodi intermedi della rete Tor) o solo un client, per accedere ad un servizio nascosto, però, è necessario l’uso di Tor da parte del client.
Un’altra caratteristica importante dei servizi nascosti di Tor è che non richiedono indirizzi IP pubblici per funzionare e possono quindi essere ospitati dietro dei firewall e dei NAT(42), oltreché consentire di selezionare a piacimento i nodi che compongono il circuito utilizzato per instradare le comunicazioni. Questa funzionalità risulta particolarmente utile nel caso in cui si voglia essere sicuri che il sistema utilizzi solo proxy siti in nazioni la cui regolamentazione relativa al trattamento dei log di utilizzo dei proxy sia particolarmente "permissiva", o peggio ancora non vi siano rapporti diplomatici o sistemi di rogatoria internazionale.
Si tenga presente che Tor può risultare un arma letale in un contesto post mortem, e non come vedremo in un contesto d’investigation.
Si consideri che Tor non offre protezione contro un ipotetico avversario globale, in grado di osservare tutte le connessioni della rete: poiché Tor è un servizio a bassa latenza sarebbe possibile correlare una connessione cifrata di partenza con una connessione in chiaro di destinazione.
Inoltre, sarebbero possibili altri attacchi all’anonimato di Tor (ma non l’identità dell’utente di partenza) anche ad un osservatore parziale della rete.
L’ultimo nodo di un circuito Tor trasmette la connessione così com’è (non cifrata da Tor) alla destinazione finale.
Se la connessione finale avviene in chiaro, l’exit node potrebbe spiare i dati trasmessi, ricavandone ad esempio password e altre informazioni.
Se la connessione è di tipo cifrato (SSL, SSH) non è possibile spiare direttamente i dati trasmessi, mentre sono comunque possibili attacchi di tipo Man in the Middle riconoscibili dal cambiamento dei certificati crittografici del server di destinazione.
Risulta ragionevole che per mitigare gli effetti collaterali di un potenziale quanto prevedibile uso improprio di tale "arma telematica", un provider dovrà inibire la modifica delle proprie pagine agli utenti anonimi che si collegano via Tor tramite un’estensione chiamata TorBlock.
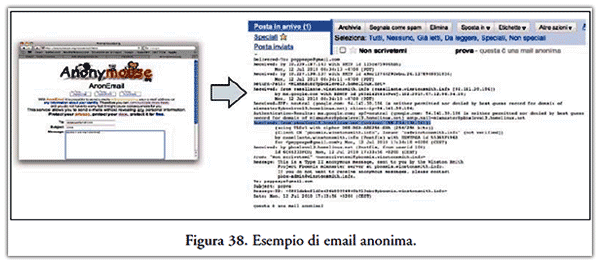
- sistema anonymous remailer, consentono la cancellazione dei dati elettronici dell’utente (rendendone di fatto impossibile l’identificazione) mediante la rimozione e sostituzione delle informazioni concernenti appunto la provenienza del mittente di una qualsiasi comunicazione(43).
È così possibile nascondere, per esempio, l’identità dei mittenti dei messaggi di posta elettronica, inducendo il server di posta a sostituire l’intestazione del mittente, ed inviare il messaggio al destinatario con intestazioni fittizie.
La Figura 38 sintetizza la tecnica appena descritta.
Si evidenzia che quest’elenco non ha la pretesa di essere esaustivo, ne tantomeno vuole demonizzare tali strumenti i quali nascono con l’obiettivo di rendere difficile l’analisi del traffico di rete al fine di ottenere il sacrosanto diritto della tutela della privacy degli internauti, ma come tutti gli strumenti della rete, ad esempio il sistema p2p, se utilizzati con obiettivi diversi da quelli per cui sono nati possono rilevarsi letali per la sicurezza di un sistema informatico. L’attività di antiforensics può essere attuata anche attraverso i browser, infatti risulta possibile non tener alcuna traccia di navigazione svolta sul computer attraverso la modalità di navigazione anonima od in incognito, fornita oramai da tutti i browser moderni.
Di seguito si riassumono i principali effetti della modalità di navigazione in incognito:
- Cookie: sono conservati in memoria per consentire alle pagine di lavorare (session cookie), ma sono rimossi quando il browser viene chiuso. Può accedere ai cookie precedentemente memorizzati;
- file Temporanei: memorizzati sul disco per consentire il funzionamento delle pagine, ma cancellati quando il browser viene chiuso;
- Cronologia: le informazioni sui siti visitati non sono memorizzate;
- Form: le informazioni sulle form compilate non sono memorizzate;
- Password: le password inserite non sono memorizzate;
- Indirizzi Digitati: gli indirizzi digitati nella barra degli indirizzi non sono memorizzati;
- Link Visitati: i link visitati non sono memorizzati.
Ultime attività di antiforensics, anche se non meno importati, possono essere messe in atto attraverso l’uso di:
- macchina virtuale, ossia un software che crea un ambiente virtuale che emula il comportamento di una macchina fisica ed in cui alcune applicazioni possono essere eseguite come se interagissero con tale macchina. In Figura 39 viene illustrato un esempio di navigazione in Internet tramite macchina virtuale;

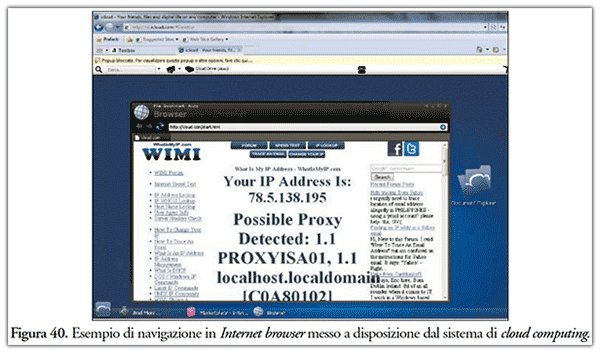
- cloud computing, ossia un paradigma distribuito che virtualizza dati, software, hardware e comunicazione dati in servizi. Le risorse usate per crimini informatici possono essere allocate remotamente. Non solo lo storage, ma anche le risorse computazionali! Interi sistemi possono essere allocati dinamicamente, utilizzati e deallocati. Le possibilità di analisi vengono così drasticamente ridotte. In Figura 40 viene illustrato un esempio di navigazione in Internet tramite sistema cloud;
- distribuzioni live o live CD, ossia veri e propri sistemi operativi e relative applicativi caricati solamente in memoria RAM, la cui volatilità di quest’ultimi rende vano qualsiasi forma di repertamento. In Figura 41 viene illustrato un esempio di distribuzione live CD;

- la parte identificata nel c.d. ultimo miglio, potrebbe essere a sua volta dotata di un’infrastruttura di rete ISO8802.3 (c.d. standard Ethernet), in cui l’assegnazione degli indirizzi IP dei rispettivi nodi non è vincolante, in quanto è sempre possibile:
• modificare l’indirizzo di rete della propria postazione, utilizzandone uno differente da quello assegnato;
• utilizzare l’indirizzo di un nodo momentaneamente spento;
• utilizzare un indirizzo contemporaneamente in uso e con ciò generando un conflitto d’indirizzamento;
• camuffare il MAC Address della scheda di rete.
6. Conclusione
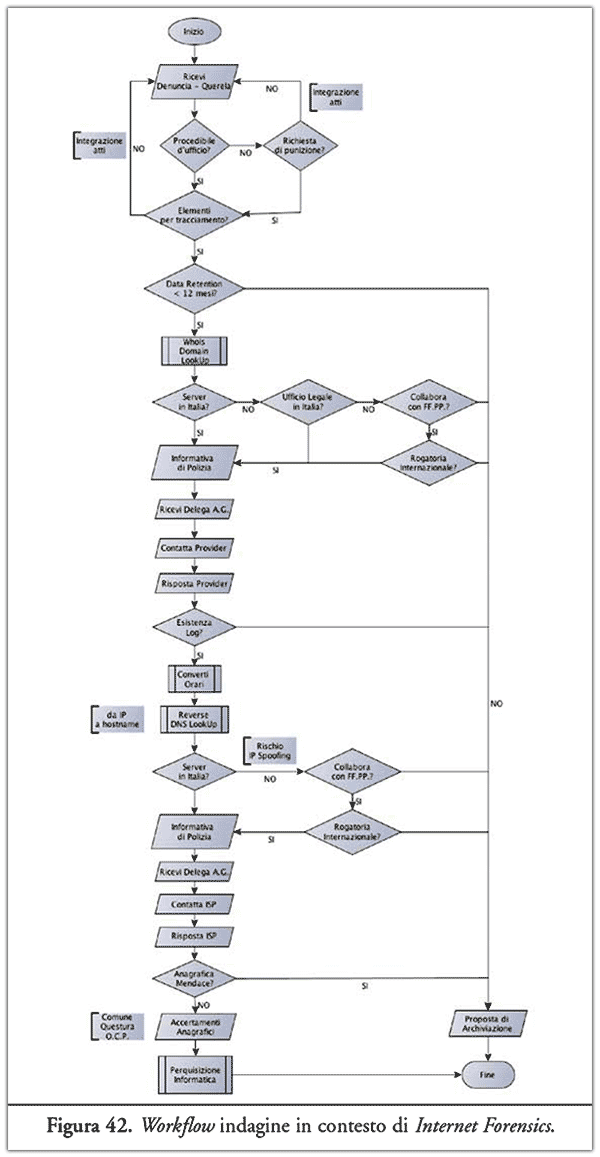
A conclusione di questo articolo, risulta utile definire una checklist delle operazioni da svolgere per un’indagine informatica in ambito Network Forensics. A tal proposito l’investigatore deve "sperare" che:
- il server ove sia presente la risorsa d’interesse per le indagini sia presente nel territorio italiano, o in un paese ove è prevista la rogatoria internazionale e che comunque questi collabori con le FF.PP.;
- non siano state adottate tecniche di anonimizzazione;
- siano rispettati i tempi di data retention, ovvero non sia passato più di un anno in modo tale da avere la certezza che l’ISP non abbia cancellato il proprio traffico telematico;
- l’ISP non abbia utilizzato una tecnica di mascheramento dell’IP, come ad esempio il sistema NAT;
- il titolare dell’utenza residenziale o business abbia fornito dati non mendaci, o sia in vita o non essere residente all’estero;
- il titolare dell’utenza Internet abiti da solo o che la macchina connessa alla rete in quel periodo sia stato esclusivamente nella sua disponibilità;
- il titolare dell’utenza Internet abbia adottato delle misure minime di sicurezza in modo tale da vietare a terzi non autorizzati l’uso della propria connessione.
Tali peculiarità procedurali vengono riassunte in Figura 42.
(1) - Reati Informatici, Codice Penale e Regolamentazione Comunitaria -
http://www.diritto.it/pdf/26626.pdf.
(2) - Elemento di prova: l’informazione che si ricava dal mezzo di prova come dato grezzo, non ancora valutato dal giudice: v. art. 65 comma 1 c.p.p.
(3) - O.C.P., OP/85, sommarie informazioni, accertamenti presso Banche Dati, apparati di video sorveglianza, celle agganciate per il traffico telefonico, etc.
(4) - Rassegna dell’Arma, anno 2009, n. 3 luglio-settembre. M. Mattiucci e G. Delfinis http://www.carabinieri.it/Internet/Editoria/Rassegna+Arma/2009/3/Studi/studi_03.htm.
(5) - RFC sta per Requests For Comments ed indica un insieme di documenti, totalmente pubblici, tramite i quali vengono fissate le regole ed i modi di funzionamento della rete Internet. I documenti sono tecnicamente indicati dalla sigla RFC seguita da un numero progressivo. Gli “RFC” contengono anche informazioni su sé stessi.
(6) - Il Phishing è una particolare tecnica di Social Engineering, la cui condotta generalmente risulta compatibile con la c.d. frode informatica p. e p. dall’art.640 ter, c.p.
(7) - Il socket è un applicazione software a bassissimo livello che si preoccupa di interpretare (in ambo i versi) i segnali elettrici (0 e 1) in comandi specificati nel protocollo TCP/IP (ovvero i pachetti) che saranno reindirizzati tramite un processo di pipeling all’applicazione (tramite la porta) che ha creato il socket.
(8) - IPv6 può fornire 340.282.366.920.938.463.374.607.431.768.211.456 indirizzi contro i 4.162.314.256 del IPv4.
(9) - Tale funzione era precedentemente svolta prevalentemente dall’ente denominato IANA (Internet Assigned Numbers Authority) delegato con mandato governativo degli Stati Uniti d’America.
(10) - Classe A: Indirizzi da 0.0.0.0 a 127.0.0.0 SM 255.0.0.0 Esistono 128 reti di classe A e per ogni rete 16.777.214 host;
- Classe B: Indirizzi da 128.0.0.0 a 191.0.0.0 SM 255.255.0.0 Esistono 16.384 reti di classe B e per ogni rete 65.534 host;
- Classe C: Indirizzi da 192.0.0.0 a 223.0.0.0 SM 255.255.255.0 Esistono 2.097.152 reti di classe C e per ogni rete 254 host;
- Classe D --> Riservata per trasmissioni Multicast.
(11) - http://www.eweek.com/images/stories/slideshows/034012_ipv6/04.jpg.
(12) - Automatic Private IP Addressing è una delle ultime caratteristiche fornite dai sistemi operativi Windows. Con APIPA, un client può automaticamente configurarsi con un IP ed una rispettiva maschera di sottorete nel caso in cui il server DHCP non sia disponibile.
(13) - http://it.wikipedia.org/wiki/Network_address_translation.
(14) - http://it.wikipedia.org/wiki/Domain_Name_System.
(15) - http://www.nic.it/
(16) - http://it.wikipedia.org/wiki/Log.
(17) - Cybercrime, intercettazioni telematiche e cooperazione giudiziaria in materia di attacchi ai sistemi informatici - http://www.personaedanno.it/index.php?option=com_content&view=article&id=29499&catid=173&Itemid=420&mese=03&anno=2009.
(18) - http://www.garanteprivacy.it/garante/doc.jsp?ID=1482111.
(19) - http://www.apogeonline.com/webzine/2011/01/07/addio-pisanu-che-cosa-cambia-ora-per-il-wifi.
(20) - Cass. Penale, sez. 5, sent. n. 6046/2008.
(21) - http://www.twt.it/newsletter/html/glossario_whois.asp.
(22) - http://it.wikipedia.org/wiki/Whois.
(23) - http://www.nic.it/crea-e-modifica.it/con-il-fax.
(24) - Content Provider, ossia il provider che fornisce contenuti.
(25) - Ora solare (CET) dal 31 ottobre al 27 marzo, corrisponde all’UTC+1. Ora legale (CEST) dal 28 marzo al 30 ottobre, corrisponde all’UTC+2.
(26) - Per una verifica si consulti http://www.timezoneconverter.com/
(27) - Autonomous System è un gruppo di router e reti sotto il controllo di una singola e ben definita autorità amministrativa.
(28) - Cybercrime, intercettazioni telematiche e cooperazione giudiziaria in materia di attacchi ai sistemi informatici - http://www.personaedanno.it/index.php?option=com_content&view=article&id=29499&catid=173&Itemid=420&mese=03&anno=2009.
(29) - Si definisce sniffing l’attività di intercettazione passiva dei dati che transitano in una rete telematica. Tale attività può essere svolta sia per scopi legittimi (ad esempio l’analisi e l’individuazione di problemi di comunicazione o di tentativi di intrusione) sia per scopi illeciti (intercettazione fraudolenta di password o altre informazioni sensibili). I prodotti software utilizzati per eseguire queste attività vengono detti sniffer ed oltre ad intercettare e memorizzare il traffico offrono funzionalità di analisi del traffico stesso.
(30) - http://www.wireshark.org/download.html.
(31) - Il Network Time Protocol, in sigla NTP, è un protocollo per sincronizzare gli orologi dei computer all’interno di una rete a commutazione di pacchetto, quindi con tempi di latenza variabili ed inaffidabili. L’NTP è un protocollo client-server appartenente al livello applicativo e in ascolto sulla porta 123.
(32) - Istituto Nazionale di Ricerca Metereologica - http://www.inrim.it/ntp/howtosync_i.shtml.
(33) - http://gnuwin32.sourceforge.net/packages/wget.htm.
(34) - https://www.hashbot.com/
(35) - Come già anticipato specificare il browser utilizzato risulta importantissimo in quanto, il contenuto del documento acquisito potrebbe cambiare proprio in sua funzione.
(36) - Xplico è un Network Forensic Analysis Tool (NFAT), ovvero un software che riesce a ricostruire i contenuti dei pacchetti catturati tramite l’utilizzo di packet sniffer come Wireshark e Tcpdump o anche con Xplico stesso, infatti questi oltre che ricostruire i pacchetti .pcap ha pure la funzione di sniffer. Xplico riesce a ricostruire tutti i dati trasportati dai protocolli come HTTP, IMAP, POP, SMTP, SIP “Voip”, FTP e TELNET, anche ricostruire le email scambiate e le chat come Facebook. Il software è sviluppato da Gianluca Costa e Andrea de Franceschi, rilasciato sotto licenza Open Source ed è installabile solo su Linux.
(37) - Un black hat (altrimenti chiamato cracker) è un hacker malintenzionato o con intenti criminali. Questo termine è spesso utilizzato nel campo della sicurezza informatica e dai programmatori per indicare una persona dalle grandi capacità informatiche, ma con fini illeciti.
(38) - Una Virtual Private Network o VPN è una rete privata instaurata tra soggetti che utilizzano un sistema di trasmissione pubblico e condiviso come per esempio Internet. Lo scopo delle reti VPN è di dare alle aziende le stesse possibilità delle linee private in affitto ad un costo inferiore sfruttando le reti condivise pubbliche, la cui riservatezza delle comunicazioni avviene sfruttando criteri crittografici.
(39) - Un Proxy Server è un computer od un’applicazione che funge da intermediario fra le richieste di un client ed un altro server.
(40) - http://exploit.blogosfere.it/2007/09/tor-arma-a-doppio-taglio.html.
(41) - http://lnx.maxpalmari.it/blog/tor-su-mac-osx/
(42) - http://it.wikipedia.org/wiki/Tor_(software).
(43) - Cybercrime, intercettazioni telematiche e cooperazione giudiziaria in materia di attacchi ai sistemi informatici - http://www.personaedanno.it/index.php?option=com_content&view=article&id=29499&catid.